Data preprocessing in machine learning with python
In this chapter, you will learn about data preprocessing in machine learning with python. Data preprocessing is a very important step in machine learning. You can visit the website Super data science and download the
Machine Learning A-Z Template Folder
Data-Preprocessing.zip
Under section 2.
After download extract the file, now we can follow the below steps in data preprocessing
Step 1:
Datasets:
In this step, you have to collect the datasets, collect if you have the datasets or create it.

Step 2:
Import Libraries:
Note: I am using the spyder editor.
Now create a file, data-processing-template.py, we are writing code snippets in the same file, now import the below libraries which are important for managing the datasets.
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Step 3:
Import the dataset file
Now import the datasets, paste the CSV file in your directory.
#Import library
import numpy as np
import matplotlib.pyplot as plt
import pandas as pand
#Import data
dataset = pand.read_csv('ml-data.csv')
X = dataset.iloc[:,:].values
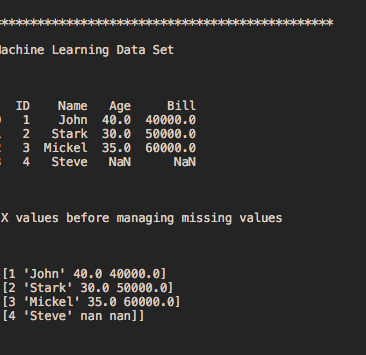
print('\n\n\n*********************************************** \n')
print('Machine Learning Data Set \n\n\n')
print(dataset)
print('\n\n\n X values before managing missing values\n\n\n')
print(X)
# Output in the console
# ***********************************************
# Machine Learning Data Set
# ID Name Age Bill
# 0 1 John 40.0 40000.0
# 1 2 Stark 30.0 50000.0
# 2 3 Mickel 35.0 60000.0
# 3 4 Steve NaN NaN
# X values before managing missing values
# [[1 'John' 40.0 40000.0]
# [2 'Stark' 30.0 50000.0]
# [3 'Mickel' 35.0 60000.0]
# [4 'Steve' nan nan]]
Now run the above code, it will print the content of the CSV file.
Note: Editor is being used, Spyder
Step 4:
Missing data:
The complete data may not available all time, there might be chances that some rows of the data go missing.
#Import library
import numpy as np
import matplotlib.pyplot as plt
import pandas as pand
#Import data
dataset = pand.read_csv('ml-data.csv')
X = dataset.iloc[:,:].values
print('\n*********************************************** \n')
print('Machine Learning Data Set \n\n\n')
print(dataset)
print('\n\n\n X values before managing missing values\n\n\n')
print(X)
#Manage missing data
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer = imputer.fit(X[:,2:4])
X[:,2:4] = imputer.transform(X[:,2:4])
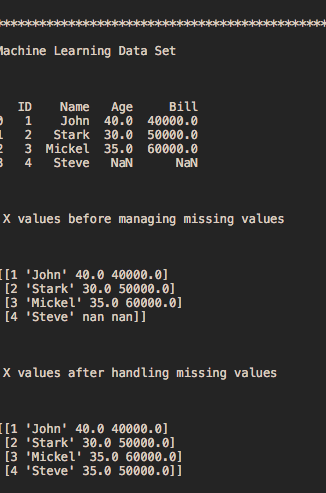
print('\n\n\n X values after handling missing values \n\n\n')
print(X)
# Output in the console
# ***********************************************
# Machine Learning Data Set
# ID Name Age Bill
# 0 1 John 40.0 40000.0
# 1 2 Stark 30.0 50000.0
# 2 3 Mickel 35.0 60000.0
# 3 4 Steve NaN NaN
# X values before managing missing values
# [[1 'John' 40.0 40000.0]
# [2 'Stark' 30.0 50000.0]
# [3 'Mickel' 35.0 60000.0]
# [4 'Steve' nan nan]]
# X values after handling missing values
# [[1 'John' 40.0 40000.0]
# [2 'Stark' 30.0 50000.0]
# [3 'Mickel' 35.0 60000.0]
# [4 'Steve' 35.0 50000.0]]
Like!! Great article post.Really thank you! Really Cool.